

Introduction: What are Web Scraping Libraries?
A web scraping library is a collection of pre-built functions and tools designed to automate data extraction from websites. These libraries make it easier for developers to collect structured data from e-commerce platforms, social media, financial websites, and more.
- Introduction: What are Web Scraping Libraries?
- 1. Best Web Scraping Libraries for Python
- 2. Best Web Scraping Libraries for JavaScript
- 3. Web Scraping Libraries for Other Languages
- 4. Choosing the Right Web Scraping Library
- 5. Legal & Ethical Considerations for Web Scraping
- Final Thoughts: Best Web Scraping Library for Your Needs
Why Use a Web Scraping Library?
✔ Reduces development time – No need to write everything from scratch
✔ Handles HTML parsing, JavaScript rendering, and API calls
✔ Provides proxy rotation, CAPTCHA solving, and headless browsing
✔ Optimized for Python, JavaScript, PHP, and other programming languages
This guide explores the best web scraping libraries for Python, JavaScript, and other popular languages.
1. Best Web Scraping Libraries for Python
Python is the most popular language for web scraping, offering powerful libraries for HTML parsing, browser automation, and data collection.
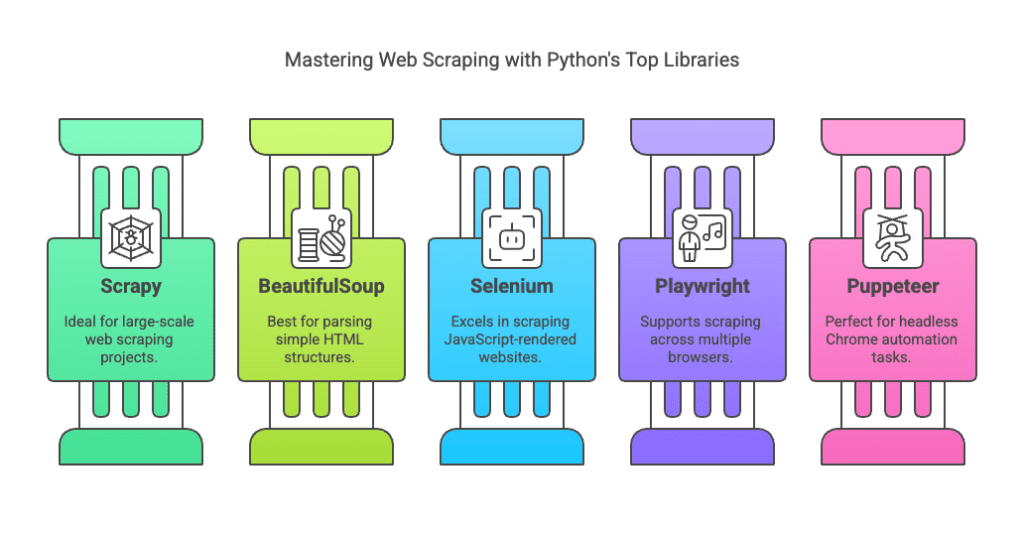
| Library | Best For | Features |
|---|---|---|
| Scrapy | Large-scale web scraping | Fast, scalable, built-in middleware |
| BeautifulSoup | Simple HTML parsing | Lightweight, easy to use |
| Selenium | Scraping JavaScript-heavy sites | Automates browser interactions |
| Playwright | Multi-browser scraping | Headless & real-time automation |
| Puppeteer (via Pyppeteer) | JavaScript-heavy sites | Chrome automation |
📖 Further Reading: Best Python Web Scraping Libraries
1. Scrapy – Best for Large-Scale Web Scraping
📌 Website: Scrapy.org
📌 Best For: High-performance web crawling and scraping
Key Features:
✔ Built-in spider framework for multi-page scraping
✔ Asynchronous requests for high-speed data extraction
✔ Supports proxy rotation & auto-throttling
📖 Learn More: Scrapy Documentation
2. BeautifulSoup – Best for Simple HTML Parsing
📌 Website: BeautifulSoup
📌 Best For: Parsing static HTML & XML documents
Key Features:
✔ Extracts tables, lists, and text data
✔ Simple CSS & XPath selector support
✔ Works with Requests & Selenium
📖 Learn More: BeautifulSoup Guide
3. Selenium – Best for Scraping JavaScript-Rendered Websites
📌 Website: Selenium.dev
📌 Best For: Automating browser interactions for JavaScript-heavy pages
Key Features:
✔ Supports Chrome, Firefox, Edge WebDrivers
✔ Automates form submissions, logins, and scrolling
✔ Ideal for scraping dynamic & AJAX content
📖 Learn More: Selenium Web Scraping Guide
4. Playwright – Best for Multi-Browser Scraping
📌 Website: Playwright.dev
📌 Best For: Scraping across multiple browser engines
Key Features:
✔ Works with Chromium, Firefox, and WebKit
✔ Detects and bypasses anti-bot measures
✔ Ideal for scraping single-page applications (SPAs)
📖 Learn More: Playwright Documentation
5. Puppeteer (Pyppeteer) – Best for Headless Chrome Automation
📌 Website: Puppeteer.dev
📌 Best For: Controlling Chrome and Chromium headless browsers
Key Features:
✔ Extracts JavaScript-rendered content
✔ Captures screenshots & PDFs of web pages
✔ Works well for SEO, testing, and automation
📖 Learn More: Puppeteer API
2. Best Web Scraping Libraries for JavaScript
JavaScript-based web scraping libraries are useful for handling dynamic pages, SPAs, and browser automation.
| Library | Best For | Features |
|---|---|---|
| Puppeteer | Headless Chrome scraping | Automates browser actions |
| Playwright | Multi-browser scraping | Supports Chromium, Firefox, WebKit |
| Cheerio | Lightweight HTML parsing | jQuery-like syntax for fast extraction |
| Axios & Node-fetch | API-based scraping | Handles HTTP requests efficiently |
📖 Further Reading: Best JavaScript Web Scraping Libraries
3. Web Scraping Libraries for Other Languages
| Language | Library | Features |
|---|---|---|
| PHP | Goutte | Simple HTTP client for scraping |
| Ruby | Nokogiri | HTML & XML parsing for Ruby apps |
| C# | HtmlAgilityPack | Web scraping framework for .NET |
| Go | Colly | Fast and efficient crawling |
📖 Further Reading: Web Scraping in Different Languages
4. Choosing the Right Web Scraping Library
| Requirement | Best Library |
|---|---|
| Large-scale scraping | Scrapy |
| Simple HTML parsing | BeautifulSoup |
| JavaScript-heavy sites | Selenium, Playwright |
| Headless Chrome automation | Puppeteer |
| Multi-browser scraping | Playwright |
| API-based scraping | Axios (JavaScript), Requests (Python) |
📖 Further Reading: How to Choose a Web Scraping Library
5. Legal & Ethical Considerations for Web Scraping
Before scraping a website, follow ethical and legal guidelines:
✔ Check robots.txt – Ensure scraping is allowed
✔ Respect website Terms of Service – Avoid violating platform policies
✔ Use proxies & rate limiting – Prevent excessive server requests
✔ Anonymize requests – Avoid detection by websites
📖 Further Reading: Is Web Scraping Legal?
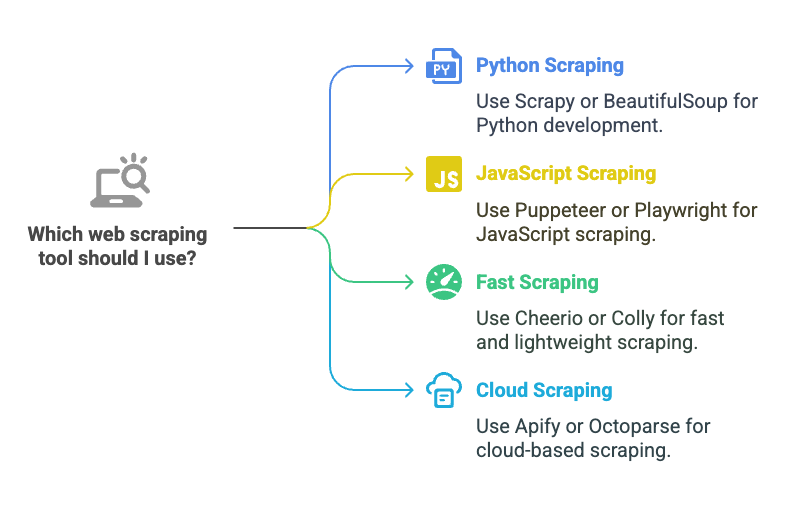
Final Thoughts: Best Web Scraping Library for Your Needs
✔ For Python developers → Use Scrapy or BeautifulSoup
✔ For JavaScript scraping → Use Puppeteer or Playwright
✔ For fast and lightweight scraping → Use Cheerio or Colly
✔ For cloud-based scraping → Use Apify or Octoparse
📩 Need professional web scraping solutions? Contact Easy Data for custom data extraction services.
Leave a Reply