

Introduction
Web scraping Amazon has become a widely used technique for businesses looking to gain insights into product prices, reviews, stock availability, and competitor strategies. With millions of sellers and a vast array of products, Amazon provides an enormous amount of valuable data. However, scraping Amazon comes with technical challenges, legal considerations, and best practices that businesses must understand before extracting data.
This guide explores how to scrape Amazon data legally, the best tools for web scraping Amazon, and how businesses can leverage data scraping to gain a competitive edge.
For advanced web scraping and data automation solutions, visit Easy Data for expert insights and scraping tools.
Why Web Scraping Amazon is Valuable
1. Price Monitoring & Competitive Analysis
- Track price fluctuations of competitors’ products.
- Identify trends and pricing strategies used by top sellers.
- Automate price adjustments for dynamic pricing strategies.
2. Product Research & Market Trends
- Gather data on bestselling products, trending categories, and emerging market demands.
- Analyze customer reviews to understand pain points and product improvement opportunities.
- Identify gaps in the market for new product launches.
3. Review Analysis & Brand Sentiment Tracking
- Collect thousands of customer reviews to measure sentiment and identify key product concerns.
- Analyze ratings and feedback trends to optimize product listings.
- Track how competitors manage customer satisfaction and resolve issues.
4. Inventory & Stock Monitoring
- Monitor stock levels of competitors to adjust supply chain strategies.
- Identify out-of-stock opportunities to increase product visibility.
- Track product availability trends in different categories.
How to Legally Scrape Amazon
Understanding Amazon’s Robots.txt Policy
Amazon’s robots.txt file provides guidelines on what parts of the site can be scraped. Some key rules include:
- Product pages are usually not explicitly disallowed, but scraping must be done responsibly.
- Search results pages and dynamic content are often blocked.
- API usage is encouraged as an alternative to scraping.
Amazon’s API: A Legal Alternative to Scraping
Amazon provides the Product Advertising API (PA-API) for accessing product data in a structured and compliant way. Businesses should consider using Amazon’s API when possible to avoid legal risks.
Best Practices for Ethical Web Scraping
- Respect robots.txt – Follow Amazon’s crawling rules.
- Use rate limiting – Avoid sending too many requests in a short period.
- Rotate IPs and user agents – Prevent detection and blocking.
- Do not scrape personal user data – Stay compliant with GDPR, CCPA, and data privacy laws.
- Cache data when possible – Reduce unnecessary requests and minimize strain on Amazon’s servers.
Best Tools for Web Scraping Amazon
1. BeautifulSoup (Python)
- Best for simple HTML parsing and data extraction.
- Requires integration with requests or Selenium for JavaScript-rendered pages.
2. Scrapy
- A powerful Python web scraping framework for large-scale data extraction.
- Supports asynchronous scraping for improved speed and efficiency.
3. Selenium
- Best for scraping dynamic content and JavaScript-heavy pages.
- Simulates user behavior to extract hidden elements.
4. Octoparse
- A no-code solution for non-developers.
- Offers built-in templates for scraping Amazon product listings.
5. Zyte (formerly Scrapinghub)
- Provides cloud-based scraping services.
- Includes proxy management to prevent IP blocking.
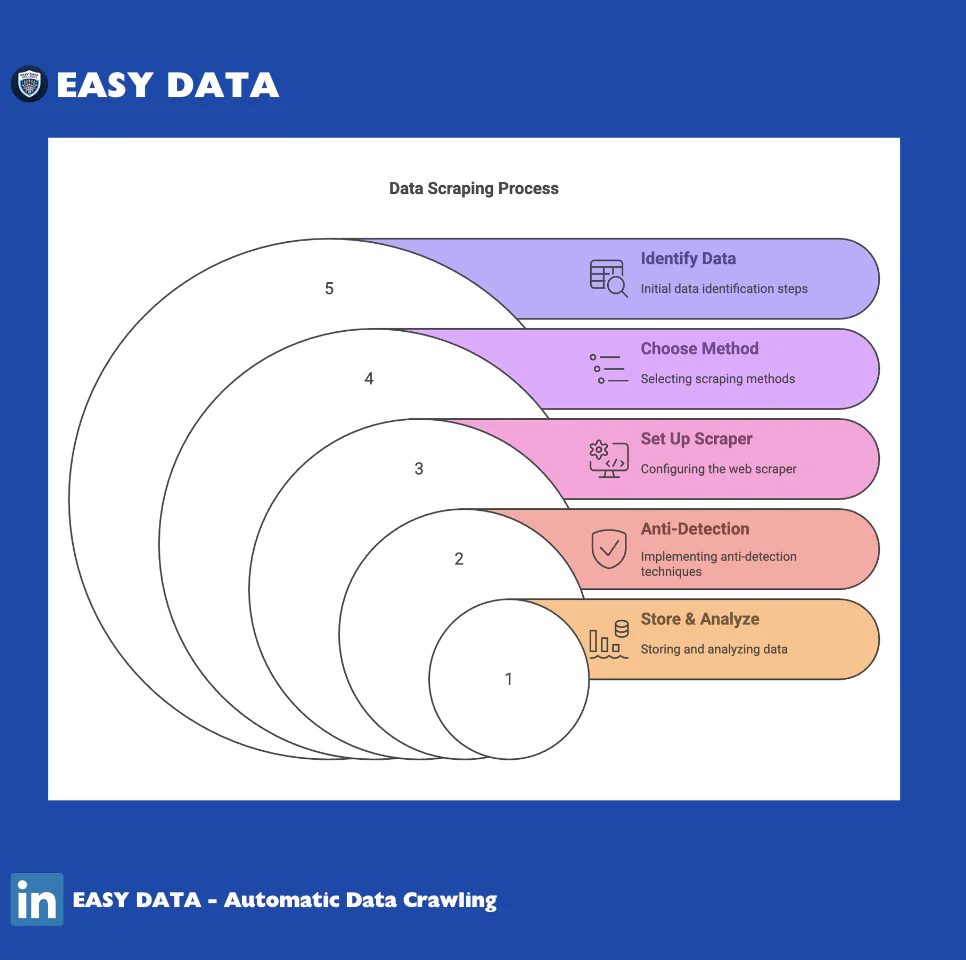
How to Scrape Amazon: A Step-by-Step Guide
Step 1: Identify the Data You Need
Decide whether you are scraping prices, reviews, stock levels, or full product details.
Step 2: Choose Your Scraping Method
- API (Preferred) – Use Amazon’s Product Advertising API for structured data.
- HTML Scraping – For product pages not available via API.
Step 3: Set Up Your Web Scraper
- Use Python with BeautifulSoup or Scrapy for code-based solutions.
- Use Selenium for JavaScript-heavy content.
- No-code options – Octoparse for easy setup.
Step 4: Implement Anti-Detection Techniques
- Rotate User Agents – Mimic different browser headers.
- Use Proxies – Avoid getting IP-banned.
- Randomize Requests – Prevent bot detection by mimicking human behavior.
Step 5: Store & Analyze the Data
- Convert scraped data into CSV, JSON, or database format.
- Use data visualization tools to generate insights.
- Leverage AI for trend analysis and automated reporting.
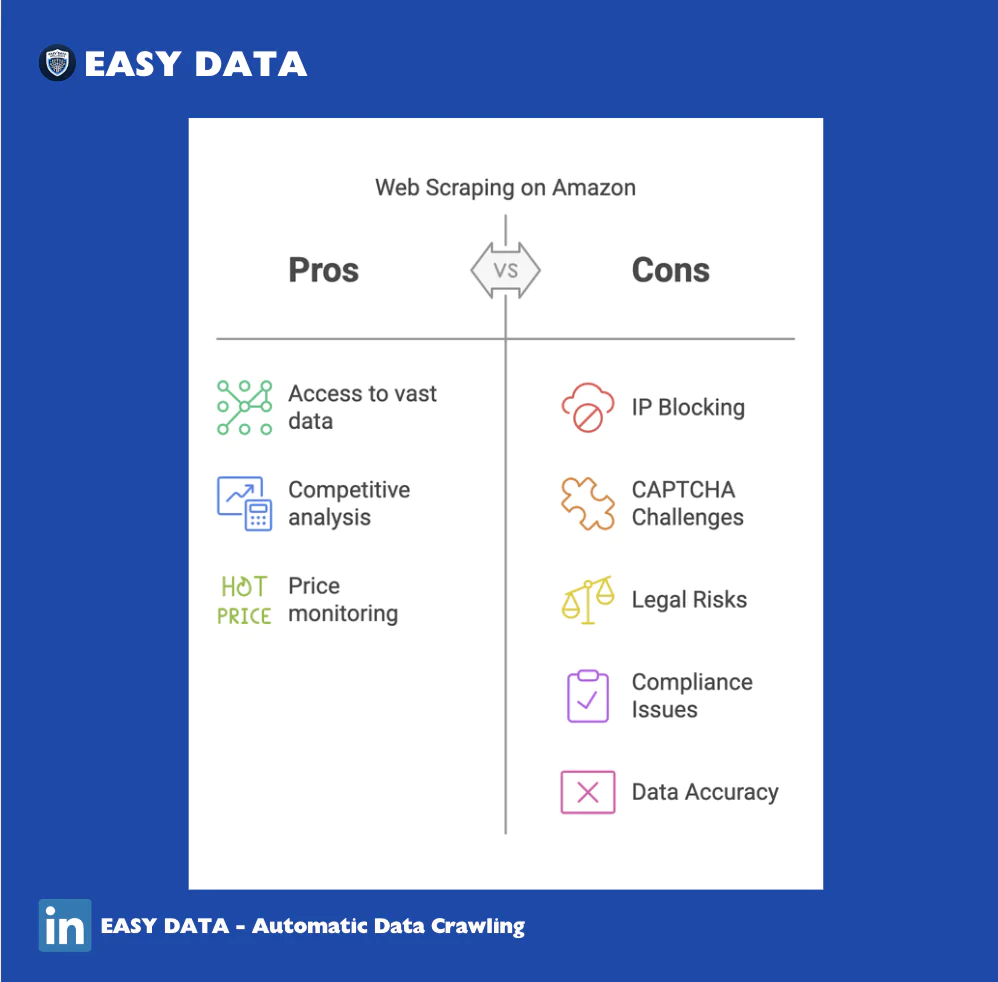
Challenges & Risks of Web Scraping Amazon
1. IP Blocking & CAPTCHA Challenges
- Amazon aggressively detects and blocks scrapers.
- Solution: Use rotating proxies and CAPTCHA solvers.
2. Legal Risks & Compliance Issues
- Unauthorized scraping may violate Amazon’s terms of service.
- Solution: Use Amazon’s API whenever possible and follow robots.txt guidelines.
3. Data Accuracy & Changes in Page Structure
- Amazon updates its HTML structure frequently, breaking scrapers.
- Solution: Use dynamic selectors and monitor changes.
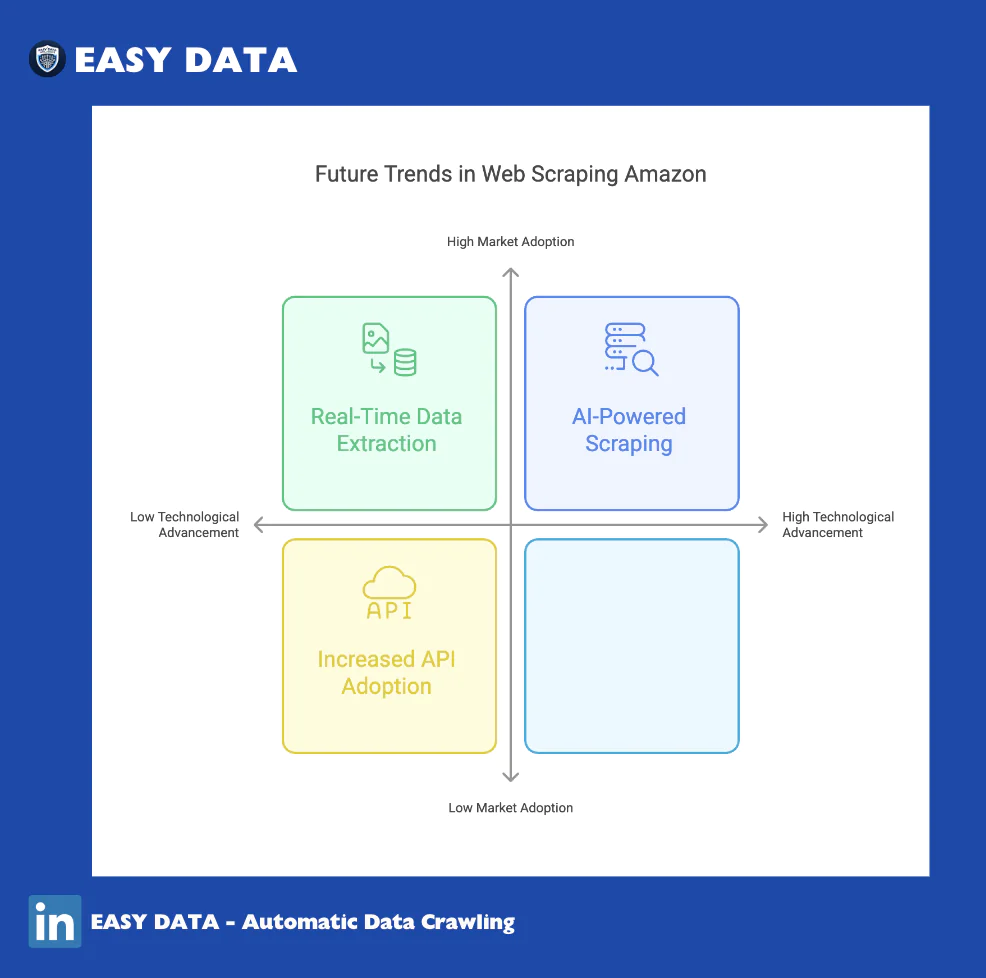
Future Trends in Web Scraping Amazon
1. AI-Powered Scraping
- Machine learning models improve accuracy and reduce detection rates.
- AI-driven bots can mimic human browsing patterns.
2. Increased API Adoption
- More businesses are shifting to API-based data collection.
- Amazon may offer expanded API access for specific business use cases.
3. Real-Time Data Extraction
- Cloud-based scrapers offer continuous, real-time monitoring.
- Businesses will rely more on automated pricing tools for dynamic adjustments.
Conclusion
Web scraping Amazon provides businesses with critical insights into pricing, inventory, reviews, and market trends. However, companies must follow ethical and legal best practices to avoid compliance risks.
To ensure efficient, risk-free data extraction, businesses should leverage Amazon’s API, proper anti-detection strategies, and advanced scraping tools.
For expert web scraping solutions, automation tools, and compliance strategies, visit Easy Data.
For further learning, check out:
Leave a Reply