

Introduction: Basics of Web Scraping
The basics of web scraping involve extracting data from websites using automated scripts. This technique helps businesses, researchers, and developers gather structured information from the internet efficiently.
Web scraping is widely used for market research, competitor analysis, price tracking, and SEO monitoring. Understanding the basics of web scraping will help you collect real-time data for better decision-making.
- Introduction: Basics of Web Scraping
- What is Web Scraping?
- Why Learn the Basics of Web Scraping?
- Essential Tools for Web Scraping
- How to Get Started with Web Scraping?
- Challenges in Web Scraping & How to Overcome Them
- Legal Considerations in Web Scraping
- Final Thoughts: The Importance of Learning the Basics of Web Scraping
What is Web Scraping?
Web scraping is the process of automatically collecting data from web pages. Instead of manually copying and pasting content, web scraping tools extract and store information in CSV, JSON, or databases for further analysis.
How Web Scraping Works
- Send an HTTP Request – The scraper accesses a target website.
- Parse the HTML Code – Extract data using HTML, CSS selectors, or XPath.
- Store the Data – Save the extracted content in a structured format.
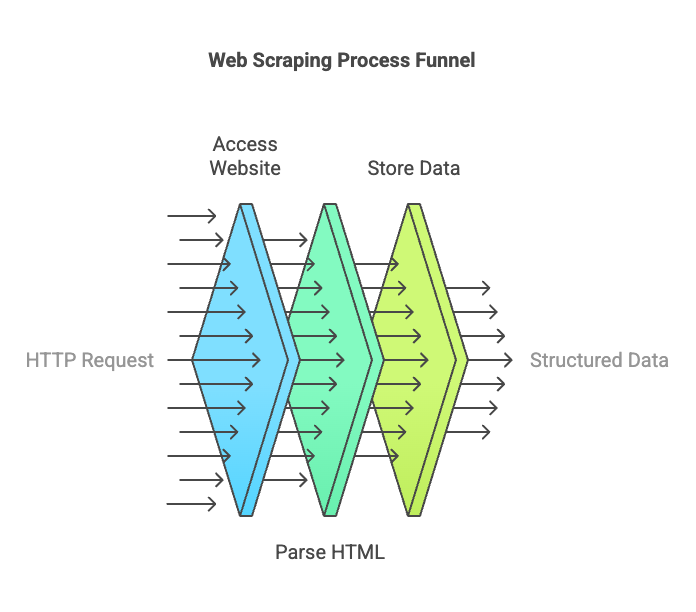
By learning the basics of web scraping, beginners can start extracting valuable business insights with ease.
Why Learn the Basics of Web Scraping?
Understanding the basics of web scraping is essential for:
✔ Automating data collection to save time
✔ Tracking competitor pricing in e-commerce
✔ Extracting SEO insights for digital marketing
✔ Generating leads for B2B and B2C businesses
✔ Analyzing financial market trends in real-time
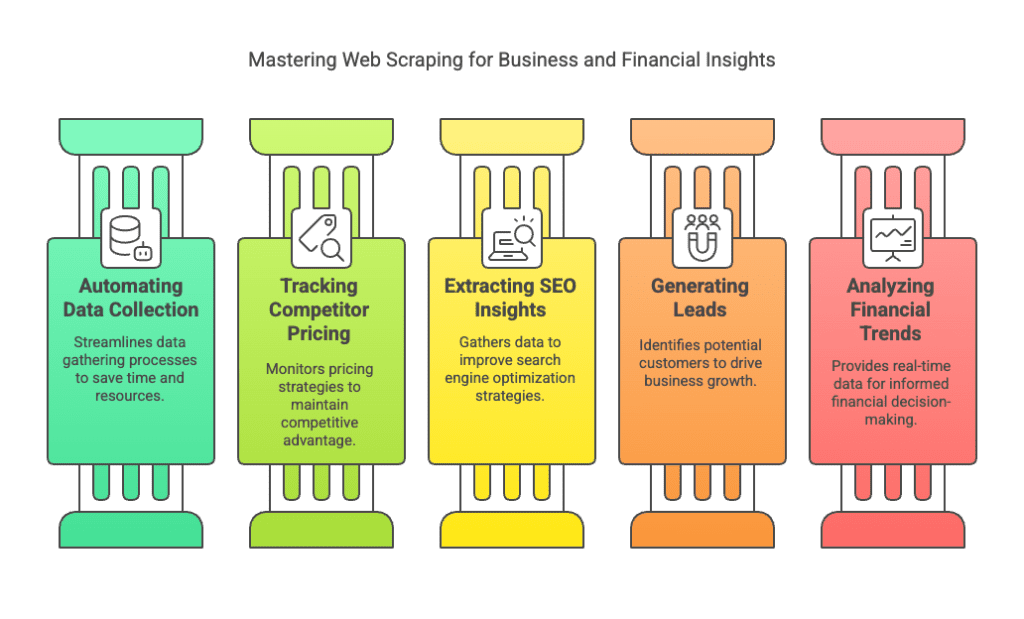
These applications show why the basics of web scraping are valuable in today’s data-driven economy.
Essential Tools for Web Scraping
1. Web Scraping Libraries
| Tool | Best For | Language |
|---|---|---|
| Scrapy | Large-scale scraping & crawling | Python |
| BeautifulSoup | Simple HTML parsing | Python |
| Selenium | JavaScript-heavy websites | Python, JavaScript |
| Puppeteer | Headless Chrome scraping | JavaScript |
| Playwright | Multi-browser scraping | Python, JavaScript |
2. HTML & CSS Selectors
Web scrapers use HTML elements like <div>, <p>, and <table> to extract data.
📌 Example: Extracting product prices from an e-commerce site.
htmlCopyEdit<div class="price">$299.99</div>
Using BeautifulSoup in Python, you can scrape the price:
pythonCopyEditfrom bs4 import BeautifulSoup
html = '<div class="price">$299.99</div>'
soup = BeautifulSoup(html, 'html.parser')
price = soup.find('div', class_='price').text
print(price) # Output: $299.99
How to Get Started with Web Scraping?
Step 1: Install Web Scraping Libraries
bashCopyEditpip install requests beautifulsoup4
Step 2: Write a Simple Web Scraper
pythonCopyEditimport requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.find_all('div', class_='product')
for product in products:
name = product.find('h2').text
price = product.find('span', class_='price').text
print(f"Product: {name}, Price: {price}")
✅ This script extracts product names and prices from an e-commerce website.
Challenges in Web Scraping & How to Overcome Them
| Challenge | Solution |
|---|---|
| JavaScript-rendered content | Use Selenium, Playwright, or Puppeteer |
| CAPTCHA & bot detection | Implement proxies & CAPTCHA solvers |
| Frequent website changes | Use dynamic CSS selectors & XPath |
| IP blocking issues | Rotate IP addresses & use headless browsers |
📖 Further Reading: How to Avoid Getting Blocked While Scraping
Legal Considerations in Web Scraping
Before scraping data, ensure compliance with:
✔ Robots.txt – Follow website guidelines for scraping permissions.
✔ GDPR & CCPA Compliance – Do not scrape personal user data.
✔ API Alternatives – Use Google API, Twitter API, or open datasets.
❌ Avoid scraping login-protected or copyrighted content without permission.
📖 Further Reading: Web Scraping & GDPR Compliance
Final Thoughts: The Importance of Learning the Basics of Web Scraping
Mastering the basics of web scraping is crucial for businesses, researchers, and developers. With the right tools, techniques, and legal compliance, you can unlock valuable insights from web data.
📩 Need web scraping solutions? Contact Easy Data for expert data extraction services.
Leave a Reply